![]()

32. Explainability vs Causality#
Here we will look at the difference between understanding how the ML model is making predictions (explainability) and what is causing the outcome (causality)
To do so we will look at a university admission example. You have been hired and asked to decided whether there is a gender bias in admission, and if there is reason for legal action against the university.
32.1. Gender and university admissions#
import pandas as pd
import sklearn as sk
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
Load the data
#load data
df_admit = pd.read_csv("/content/UCB_admission.csv")
#take a look
df_admit.head()
Check for missing data, and the types of data we are dealing with.
?
Visualize the data
Let’s do some exploratory data analysis before build a model.
#plot admissions by reported gender
?
#plot admissions by department
?
What patterns do you see?
Do these visualizations help you answer if there is systematic bias in acceptance rates by gender?
32.2. Preprocessing#
We have some categorical predictor variables so let’s do some preprocessing!
Let’s one-hot-encode ‘dept’
#convert the categorical variable into dummy variables
df_cat = pd.get_dummies(df_admit['dept'])
#concat the dummy variables back onto the dataframe
df_admit = pd.concat([df_admit, df_cat], axis = 1)
#drop the original categorical variable
df_admit = df_admit.drop(['dept'], axis=1)
#take a look
df_admit
Let’s encode the binary predictor variable gender as 0/1
from sklearn.preprocessing import LabelEncoder
#build the encoder
my_gen = LabelEncoder()
#fit and transform the gender column
df_admit['applicant.gender'] = my_gen.fit_transform(df_admit['applicant.gender'].values.reshape(-1,1))
#take a look
df_admit
Finally, let’s do a training testing split on the data.
#split data into predictors (X) and target (y)
X = df_admit.drop('admitted', axis=1)
y = df_admit['admitted']
#split these data into training and testing datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=234)
32.3. Build a model#
Can we predict admission based on reported gender?
Build a random forest for predicting admission using gender.
from sklearn.ensemble import RandomForestClassifier
#1. Build the model
forest_classifier = RandomForestClassifier(n_estimators=100, bootstrap=True, max_features=0.8, max_samples=0.8, max_depth=5,random_state=243)
#2. Fit the model to the data
forest_classifier.fit(X_train, y_train)
Let’s see what variables the model learnt were important for predicting if someone will be admitted.
from sklearn.inspection import permutation_importance
#model interpretation
rel_impo = permutation_importance(forest_classifier, X_test, y_test,n_repeats=30,random_state=243)
#build a dataframe to store the results
df_rel_impo = pd.DataFrame({"feature":X_test.columns,"importance":rel_impo.importances_mean, "sd":rel_impo.importances_std})
#take a look
df_rel_impo.sort_values(by='importance', ascending=False,inplace=True)
df_rel_impo
Let’s also plot the permutation feature importance
sns.barplot(data=df_rel_impo, y='feature', x='importance')
Finally, let’s ask our model to do some counterfactual. These are “what-if” questions that we can use to see what would have happened if an applicant would be admitted base on if they reported a different gender.
# 1. Create a dataframe for the conterfactual you want to test
df_question = pd.DataFrame({
'applicant.gender': [0, 1],
'school_score': [50, 50],
'A': [0, 0],
'B': [0, 0],
'C': [1, 1],
'D': [0, 0],
'E': [0, 0],
'F': [0, 0],
})
# 2. Use the model to get probabilities
question_pred_proba = forest_classifier.predict_proba(df_question)
# 3. Wrap into a DataFrame for readability
proba_df = pd.DataFrame(
question_pred_proba,
columns=forest_classifier.classes_,
index=['Female', 'Male']
)
print(proba_df)
What is the model telling us when it comes to the impact that gender has on if someone will be admitted to UC Berkeley?
32.4. Fit the model again, this time with a reduced model#
To highlight how our model changes interpretation base on what variables we include, let’s fit the model again… this time without accounting for department.
Let’s remove department.
#fit a smaller model - remove departments
X_train_small = X_train.drop(["A","B","C","D","E","F"], axis=1)
X_test_small = X_test.drop(["A","B","C","D","E","F"], axis=1)
Let’s fit a new random forest model.
#1. Build the model
forest_classifier_small = RandomForestClassifier(n_estimators=100, bootstrap=True, max_features=0.8, max_samples=0.8, max_depth=5,random_state=243)
#2. Fit the model to the data
forest_classifier_small.fit(X_train_small, y_train)
Let’s calculate permutation feature importance.
#model interpretation
rel_impo_small = permutation_importance(forest_classifier_small, X_test_small, y_test,n_repeats=30,random_state=243)
#build a dataframe to store the results
df_rel_impo_small = pd.DataFrame({"feature":X_test_small.columns,"importance":rel_impo_small.importances_mean, "sd":rel_impo_small.importances_std})
#take a look
df_rel_impo_small.sort_values(by='importance', ascending=False,inplace=True)
df_rel_impo_small
sns.barplot(data=df_rel_impo_small, y='feature', x='importance')
Then let’s ask the model a counterfactual question about how gender might impact admissions.
# 1. dataframe for the scenarios you want to test
df_question = pd.DataFrame({
'applicant.gender': [0, 1],
'school_score': [0, 0]
})
# 2. get probabilities
question_pred_proba = forest_classifier_small.predict_proba(df_question)
# 3. take a look
proba_df = pd.DataFrame(
question_pred_proba,
columns=forest_classifier.classes_,
index=['Female', 'Male']
)
print(proba_df)
You should see that now the model predicts quite a bit of difference. Which one is right?
The answer is both!
It’s just that each model is telling us something different. By containing different predictor variables, the models are addressing a different question.
32.5. Statistical confounds#
Statistical confounds make it hard to determine the causal nature of the patterns we find in ML model results. This is the case with traditional statistical models as well! We need to be careful about how we explain how a model makes predictions and the causal nature of those patterns.
In the case of the admissions and gender, there is a process where genders are not applying to departments in equal measure.
That is, the causal relationships that generated this data might look something like:
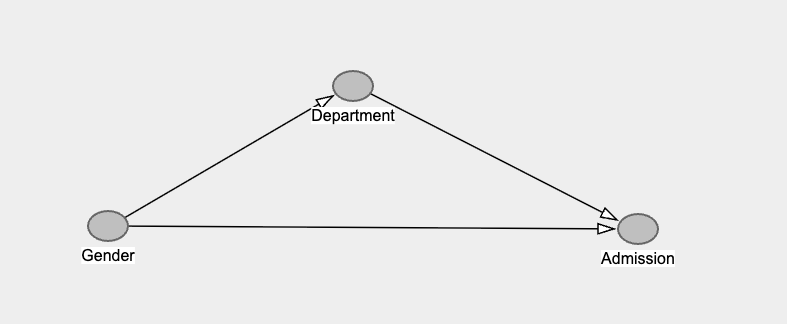
The model with all the predictors in, is estimating the bottom line going from Gender to Admission. That is called the “direct effect” of Gender.
While the model without Department is estimating the lines going from Gender to Department then to Admission, and the line going from Gender to admission. This is called the “total effect” of Gender.

Try going back and changing/removing the fixed random state, do you get the same answer each time.
Also, school score is just a random number! I added it in as a way for you to double check if your model is overfitting. See if you can build random forest models that correctly give zero weight to school score, and yet still pull out the impacts of gender and department.
32.6. Feature selection by performance#
What happens if we use recursive feature extraction to automatically choose parameters for us?
from sklearn.feature_selection import RFECV
#min number of variables/features
min_features_to_select = 1
#build the feature selection algorithm
rfecv = RFECV(estimator=forest_classifier, step=1, cv=5, min_features_to_select=min_features_to_select)
#fit the algorithm to the data
rfecv.fit(X_train, y_train)
print("Optimal number of features : %d" % rfecv.n_features_)
Let’s take a look at a plot
import matplotlib.pyplot as plt
import numpy as np
# Number of features tested
n_features = range(
rfecv.min_features_to_select,
len(rfecv.cv_results_["mean_test_score"]) + rfecv.min_features_to_select
)
# Plot the scores
plt.figure(figsize=(8,6))
plt.plot(n_features, rfecv.cv_results_["mean_test_score"], marker="o")
plt.xlabel("Number of features selected")
plt.ylabel("CV score (mean across folds)")
plt.title("Recursive Feature Elimination with Cross-Validation (RFECV)")
selected_features = X_train.columns[rfecv.support_] print(“Selected features:”, list(selected_features))
What did the feature selector suggest is the “best” features to include?
Does this model help you answer the question about if one gender is more likely to be admitted to UC Berkeley?
32.6.1. Bonus#
Redo the exercise above this time using decision trees, or linear regression.
from sklearn.linear_model import LinearRegression
# build
LR1 = LinearRegression()
# fit
LR1.fit(X_train, y_train)
32.7. Further reading#
If you would like to know more about causal inference you might like:
The book of why (link)
Causal Inference and Discovery in Python (link)
If you would like the notebook without missing code check out the full code version.